и если верить одному из людей которые продают эти SOTA модели https://youtu.be/mYDSSRS-B5U?si=Wu2mXkxTnqt7aJsR&t=1851 это в ближайшие 2 года не изменится
> I expect the price of providing a given level of intelligence to go down. I expect the price of providing the frontier of intelligence which will which will provide kind of increasing economic value that might go up or it might go down. My guess is it probably stays about where it is.
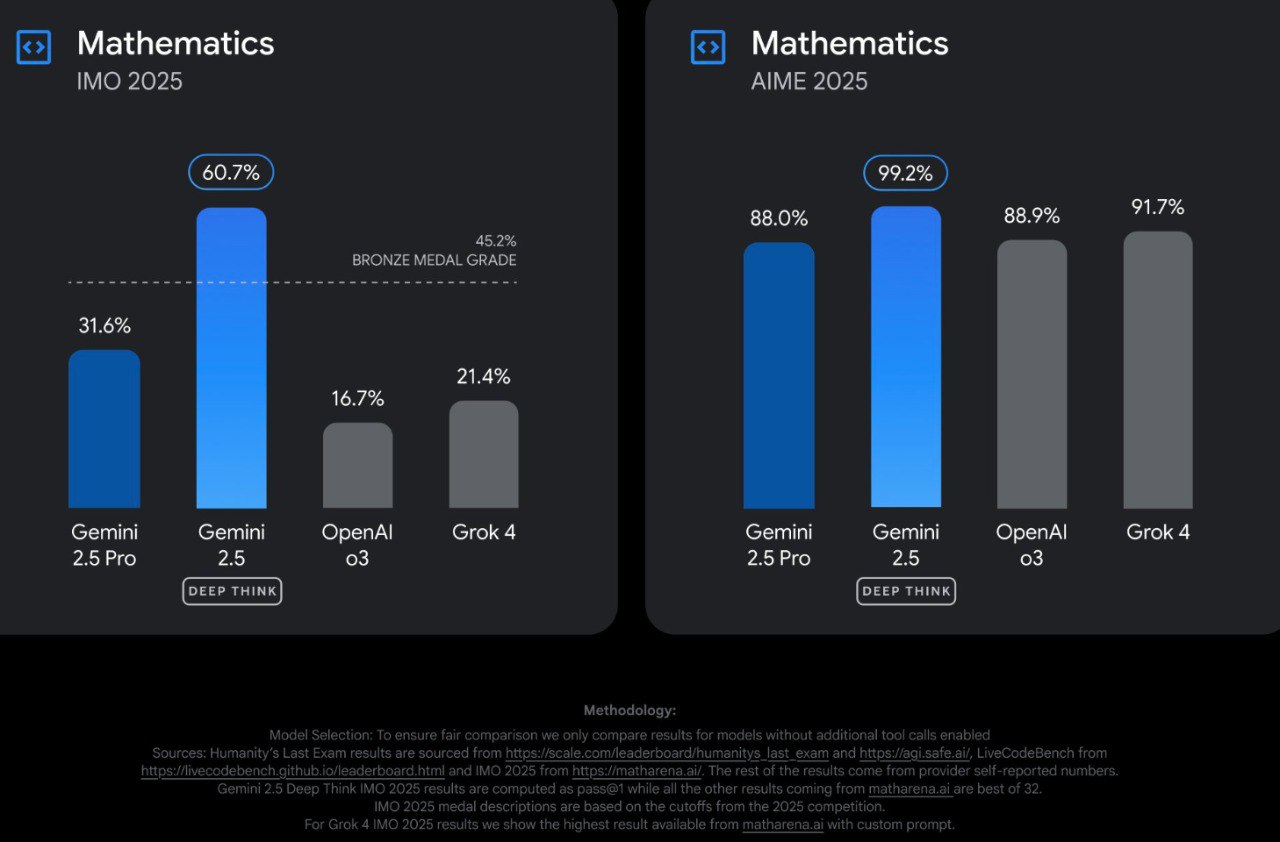
на этой картинке самое смешное конечно что AIME бенчмарк по сути пал. больше нет смысла его прогонять. что в общемто логично, ибо aime это по сути всего лишь этап отборочного тура на imo.
сначала школьники старшеклассники решают AMC -> потом лучшие из них решают AIME -> потом для лучших из лучших проводят национального уровня USAMO -> и уже наконец победителей отправляют на международный IMO
так что если 2.5pro deepthink набирает бронзу на IMO, ясный пень что он “прошел” уже AIME, duh!
но во всем этом пиршестве “размышляющих” моделей есть одна проблема. это прозвучит странно. но, после изучения (при помощи grok4) решений IMO25 которые openAI запостили вот тут https://github.com/aw31/openai-imo-2025-proofs выяснилась забавная вещь. эти штуки выполняют интеллектуальную работу да, но они не думают. ща постараюсь пояснить что я имею ввиду
возьмем скажем P2. вот объяснение решения человека https://www.youtube.com/watch?v=A4_bYF97IQI это геометрическое решение, с диаграммами, рисованием воображаемых линий и т.д. понятное и логичное. при его рассказе в голове возникает тот самый “ага!” момент когда проблема предстает в доступном и простом виде если на нее посмотреть под нужным углом
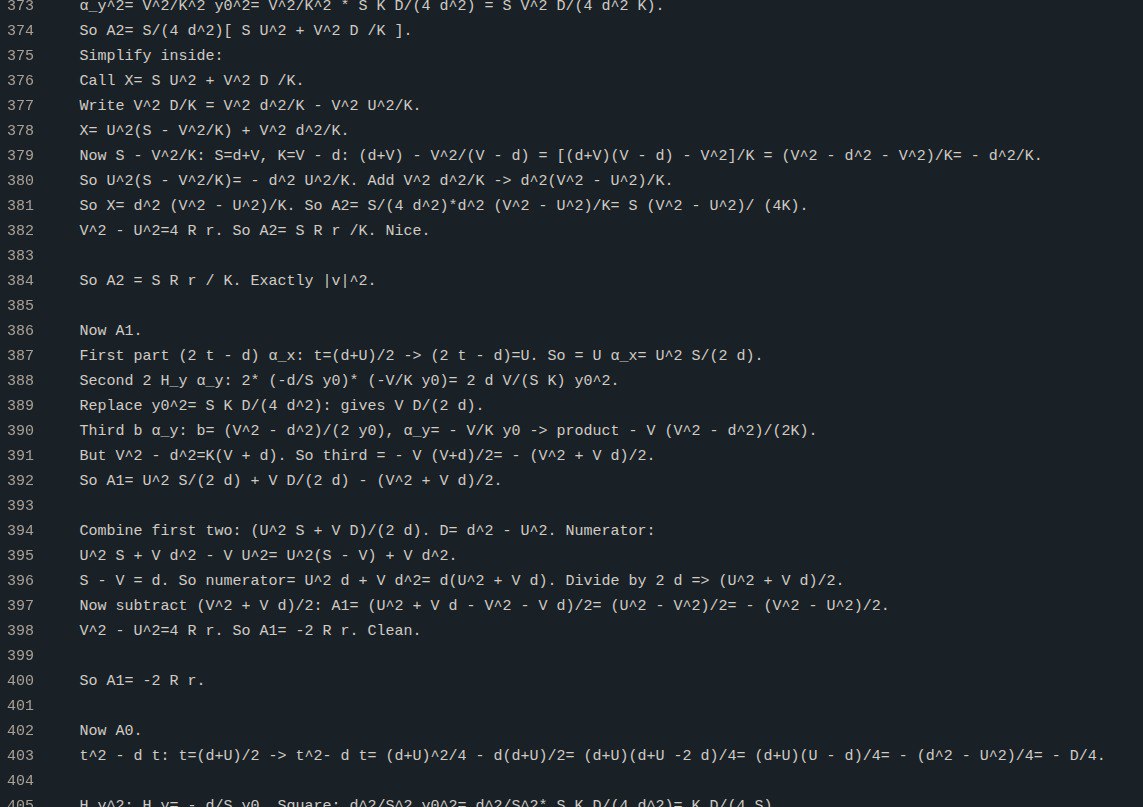
grok4 оценил это решение так в сравнении с человеческим: > For Understanding the Geometry: The geometric proof wins—it’s more insightful and reveals symmetries/collinearities/incenters that make the problem “click.” It’s likely the “intended” solution for a contest like IMO, where synthetic proofs are prized. For Verification/Rigor: The algebraic proof is superior—it’s exhaustive and leaves no doubt (e.g., Δ=0 is irrefutable). Great for skeptics or computational checks.

но любопытно тут другое. в процессе решения своего LLM точно вывела все необходимые для доказательства формулы, которые должны были ей указать на внутреннюю геометричность проблемы, но она это не отметила. т.е. ей до фонаря что именно она делает, она не видит за деревьями леса.

но вот интуитивной красоты она не видит. во всяком случае в этом классе проблем. она при этом не глупая. она выполняет интеллектуальный труд на который немногие способны. но она при этом не “думает”. не осознает и не подмечает.
возможно именно поэтому никто из AI лабораторий не смог решить P6 в этом году. в человеческом решении https://www.youtube.com/watch?v=fgXg9CdCDcs мне больше всего нравится вот этот комментарий: решением является паттерн самой примитивной моб фермы в майнкрафте который надо выложить шерстяными коврами чтоб пауки не спавнились
да, кстати еще одна забавная вещь вскрылась сегодня. https://youtu.be/EEIPtofVe2Q?si=Xje-EdXOw_kdpHjc&t=349 тот факт что эта самая модель openAI взявшая золото такая скупая на слова это осознанный выбор самих ученых из openAI. грубо говоря раз для доказательств математики не обязательно их объяснять, то они буквально не стали тренировать ее чтоб она человеко-понятно свои выкладки делала.
вот прям, как ей алгебра в голову лезет так она и шлепает, без прелюдий и реверансов. изредка сама себя похваливает “great.”, “exactly.” и “clean.” это значит что она уверена что на верном пути. если она неуверена или незнает как решить так и говорит: no answer.
т.е. они на полном серьезе могут произвести модель которая будет очень умной но при этом скупой на слова. шах и мат, для всех сторонников теории “ну это просто попугаи которые воспроизводят слова, поэтому нам кажется что эти слова осмысленны”
нет. эта штука, чтоб оно не было, воспроизводит уже не слова. и не куски речи. она в процессе обучения способна впитать в себя те самые абстрактные знания. а в какой форме их выражать это по выбору авторов модели. завтра они решат что лушчем выражением являются картины в духе поллока и натренируют ее выкладывать алгебраические взаимосвязи на холсте
ах да, и вишенка на торте в том что вот эти люди которые достаточно умные чтоб разработать модель берущую золото на олимпиаде признаются что сами они не могут решить P6 задание “даже за месяц с подсказками”.
и это при этом они потратили “очень много” ресурсов в попытках чтоб модель решила P6. но сколько она не пыталась, не смогла, каждый раз в конце признаваясь что она нашла “no answer”.
т.е. модель в состоянии понять что ей не по зубам.
по сути — экскаватор. во много раз превосходящий силы одного копателя лопатой. но абсолютно не осознающего что именно она копает и зачем.
и теперь такой будет в руках у каждого кто хочет выкопать траншею мыслей и идей за 300 долларов/мес. всем остальным придется копать лопаткой, по старинке
